 inteligencia de amenazas
inteligencia de amenazas
No todos los profesionales de la ciberseguridad creen que vale la pena el esfuerzo de averiguar exactamente quién mueve los hilos detrás del malware que afecta a su empresa. El algoritmo típico de investigación de incidentes funciona más o menos así: el analista encuentra un archivo sospechoso → si el antivirus no lo detectó, lo coloca en un entorno de pruebas para probarlo → confirma alguna actividad maliciosa → añade el hash a la lista de bloqueo → va a tomar un café. Estos son los pasos por seguir para muchos profesionales de la ciberseguridad, en especial cuando están saturados de alertas o no tienen las habilidades forenses para desentrañar un ataque complejo pieza por pieza. Sin embargo, cuando se trata de un ataque dirigido, este enfoque es un billete de ida hacia el desastre, y este es el motivo.
Si un atacante va en serio, rara vez se queda con un solo vector de ataque. Existe una buena posibilidad de que el archivo malicioso ya haya desempeñado su papel en un ataque de varias etapas y ahora sea casi inútil para el atacante. Mientras tanto, el adversario ya se ha instalado en lo profundo de la infraestructura corporativa y está ocupado operando con un conjunto de herramientas completamente diferente. Si quiere eliminar la amenaza para siempre, el equipo de seguridad debe descubrir y neutralizar toda la cadena de ataque.
Pero ¿cómo se puede hacer esto de manera rápida y efectiva antes de que los atacantes logren causar un daño real? Una forma es sumergirse en el contexto. Al analizar un solo archivo, un experto puede identificar exactamente quién está atacando a su empresa, descubrir con rapidez qué otras herramientas y tácticas emplea ese grupo específico y luego analizar la infraestructura en busca de amenazas relacionadas. Hay muchas herramientas de inteligencia de amenazas para hacer esto, pero te mostraré cómo funciona con nuestro Kaspersky Threat Intelligence Portal.
Un ejemplo práctico de por qué es importante la atribución
Supongamos que subimos un malware que hemos descubierto a un portal de inteligencia sobre amenazas y descubrimos que suele ser utilizado, por ejemplo, por el grupo MysterySnail. ¿Qué nos dice eso realmente? Veamos la información disponible:
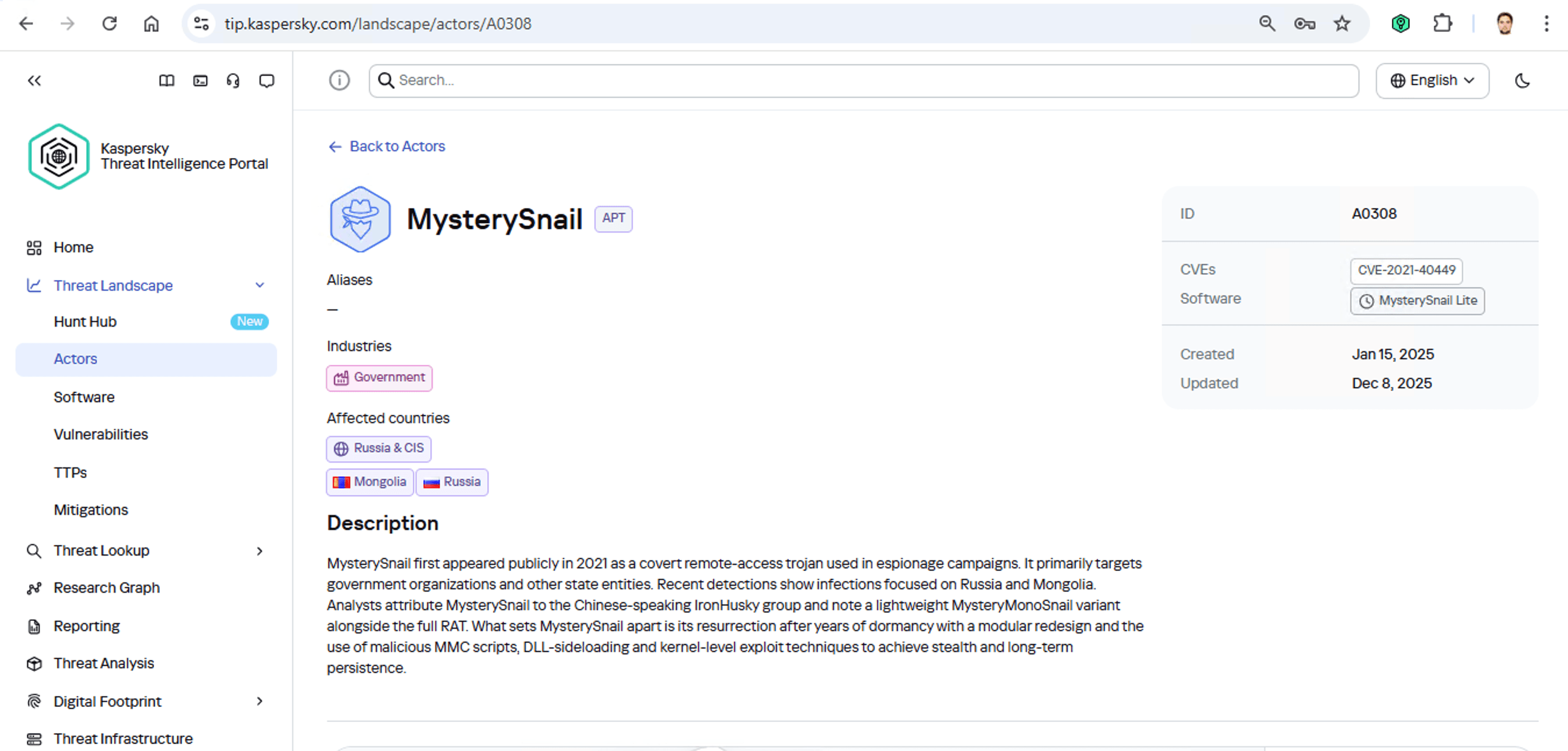
En primer lugar, estos atacantes tienen como objetivo las instituciones gubernamentales tanto en Rusia como en Mongolia. Es un grupo de habla china que generalmente se enfoca en el espionaje. Según su perfil, se implantan en la infraestructura y se mantienen ocultos hasta que encuentran algo que vale la pena robar. También sabemos que suelen aprovechar la vulnerabilidad CVE-2021-40449. ¿Qué tipo de vulnerabilidad es esa?
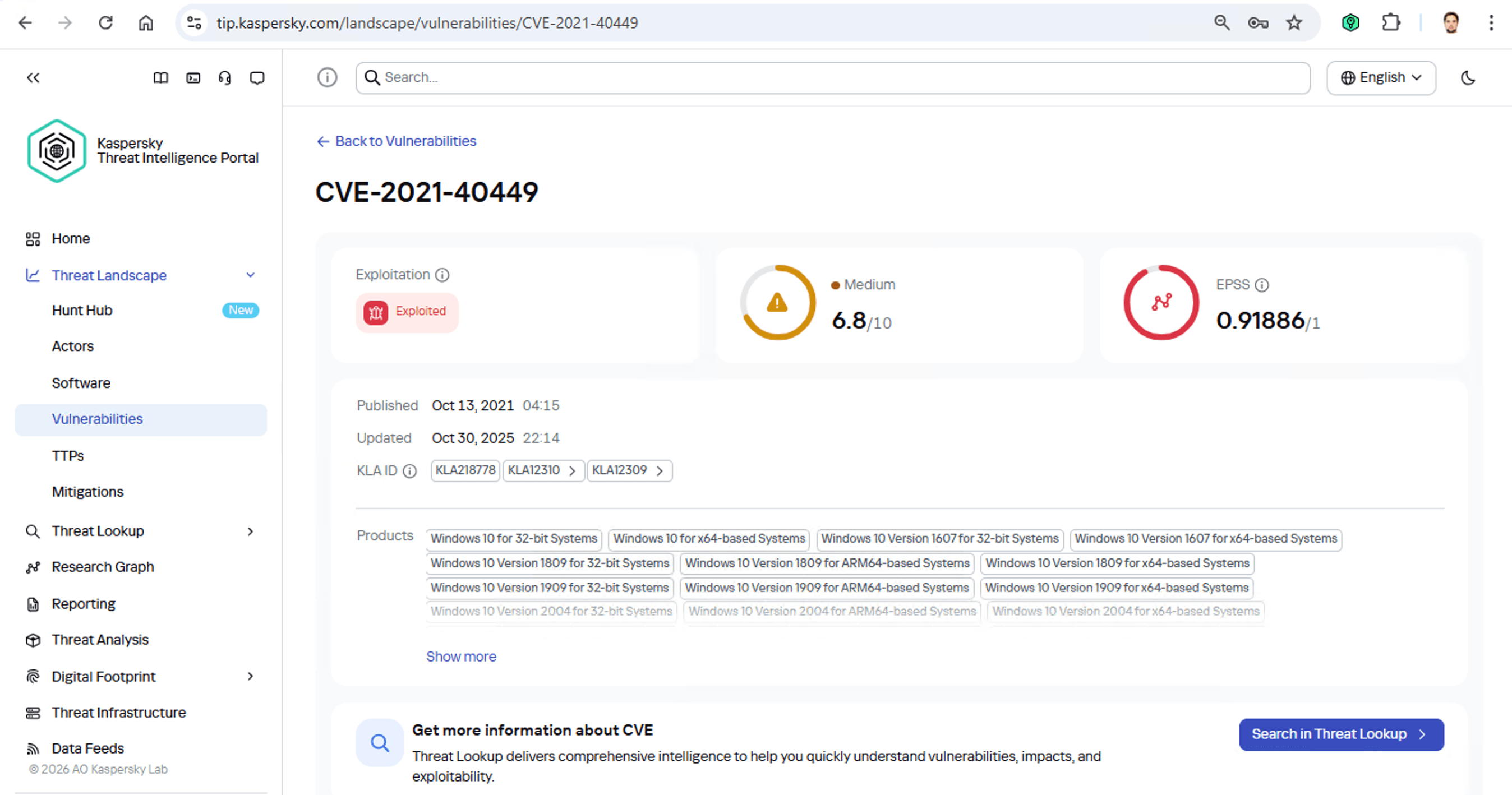
Como podemos ver, es una vulnerabilidad de escalada de privilegios, lo que significa que se usa después de que los ciberdelincuentes ya se han infiltrado en la infraestructura. Esta vulnerabilidad tiene una clasificación de gravedad alta y se explota mucho en entornos reales. Entonces, ¿qué software es realmente vulnerable?
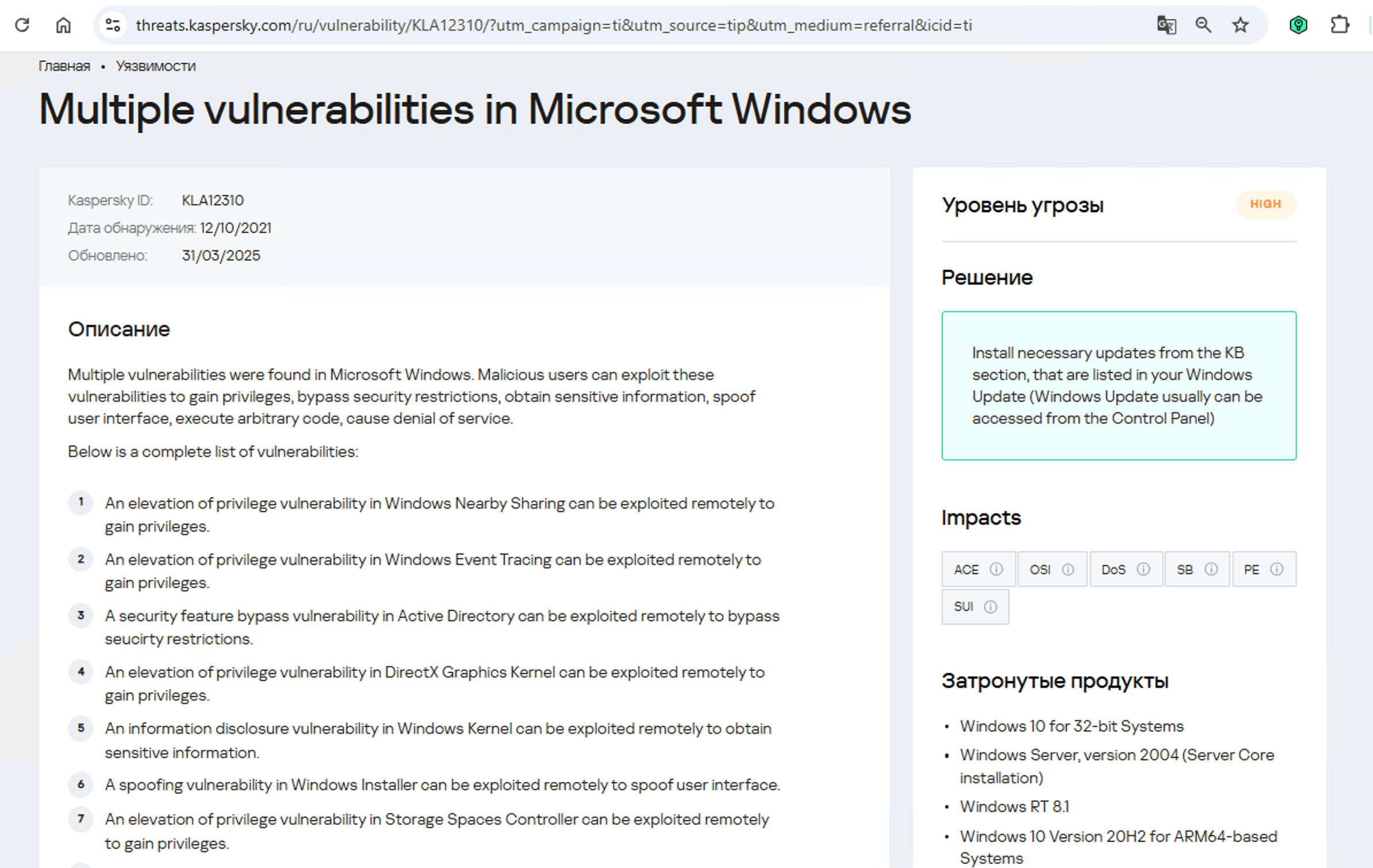
Microsoft Windows. Es hora de volver a comprobar si el parche que corrige esta vulnerabilidad realmente se ha instalado. Muy bien, además de la vulnerabilidad, ¿qué más sabemos sobre los cibercriminales? Resulta que tienen una forma peculiar de verificar las configuraciones de red: se conectan al sitio público 2ip.ru:

Tiene sentido añadir una regla de correlación al SIEM para detectar ese tipo de comportamiento.
Ahora es el momento de leer más sobre este grupo y recopilar indicadores de compromiso adicionales (IOC) para la supervisión de SIEM, así como reglas YARA (descripciones de texto estructuradas que se utilizan para identificar malware) listas para usar. Esto nos ayudará a rastrear todos los tentáculos de este kraken que ya se han infiltrado en la infraestructura corporativa y nos garantizará que podamos interceptarlos rápidamente si intentan entrar de nuevo.
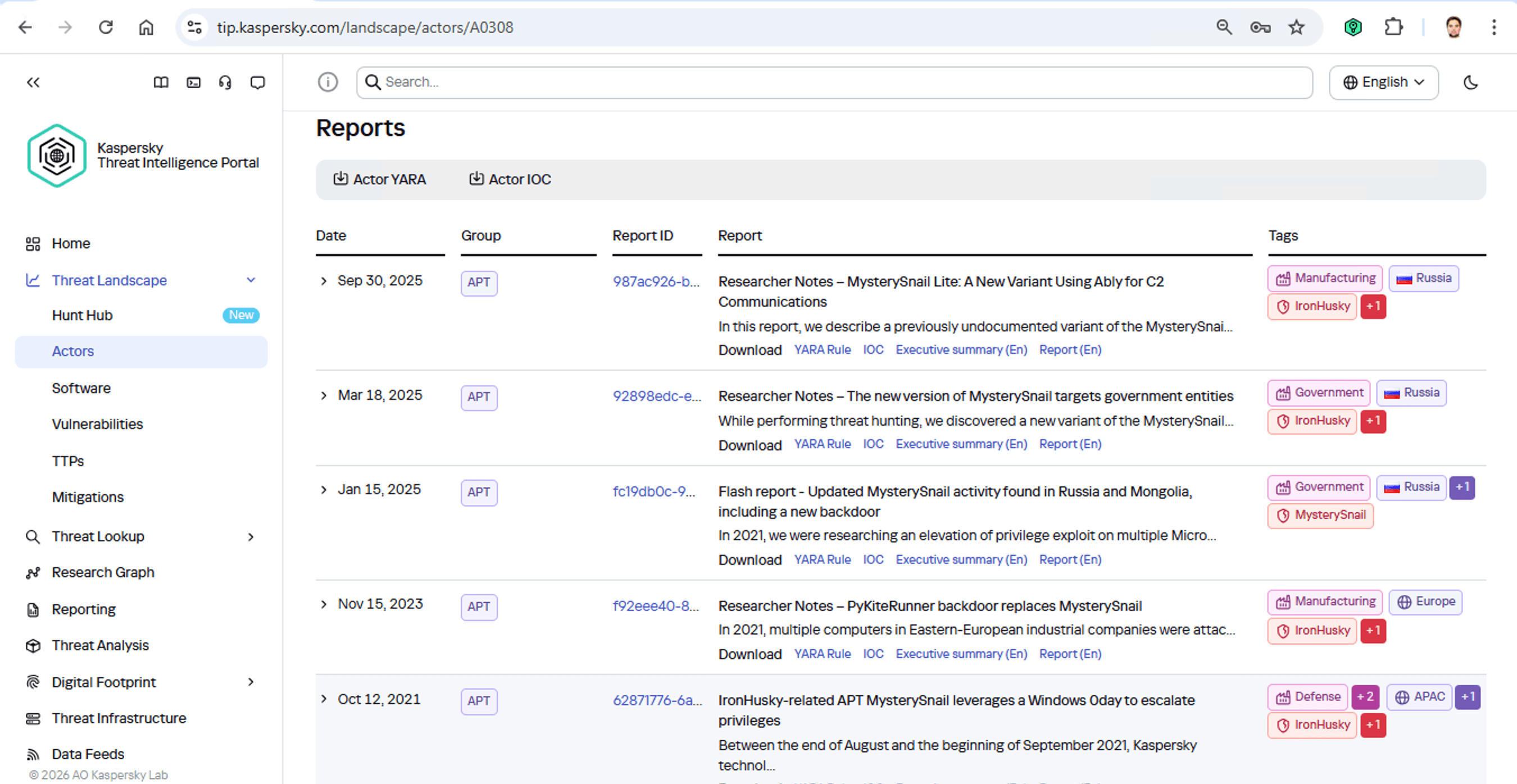
Kaspersky Threat Intelligence Portal proporciona una tonelada de informes adicionales sobre ataques MysterySnail, cada uno completo con una lista de IOC y reglas YARA. Estas reglas de YARA se pueden usar para analizar todos los endpoints, y esos IOC se pueden sumar a la SIEM para una supervisión constante. Ya que estamos, revisemos los informes para ver cómo estos atacantes manejan la exfiltración de datos y qué tipo de datos suelen buscar. Ahora sí podemos tomar medidas para evitar el ataque.
Y así, MysterySnail, la infraestructura ahora está equipada para encontrarte y responder de inmediato. ¡No más espionaje!
Métodos de atribución de malware
Antes de ahondar en métodos específicos, debemos dejar una cosa en claro: para que la atribución funcione de verdad, la inteligencia de amenazas proporcionada necesita una base de conocimientos masiva de las tácticas, técnicas y procedimientos (TTP) que usan los actores de la amenaza. El alcance y la calidad de estas bases de datos pueden variar muchísimo entre proveedores. En nuestro caso, incluso antes de crear nuestra herramienta, pasamos años rastreando grupos conocidos en varias campañas y registrando sus TTP, y hoy en día seguimos actualizando activamente esa base de datos.
Con una base de datos de TTP implementada, se pueden implementar los siguientes métodos de atribución:
- Atribución dinámica: se identifican TTP mediante el análisis dinámico de archivos específicos y luego se compara ese conjunto de TTP con los de grupos de ciberdelincuentes conocidos.
- Atribución técnica: se buscan superposiciones de código entre archivos específicos y fragmentos de código que se sabe que son utilizados por ciertos grupos criminales en su malware.
Atribución dinámica
La identificación de TTP durante el análisis dinámico es relativamente sencilla de implementar. De hecho, esta funcionalidad ha sido un elemento básico de todos los entornos de pruebas modernos durante mucho tiempo. Por supuesto, todos nuestros entornos de pruebas también identifican los TTP durante el análisis dinámico de una muestra de malware:
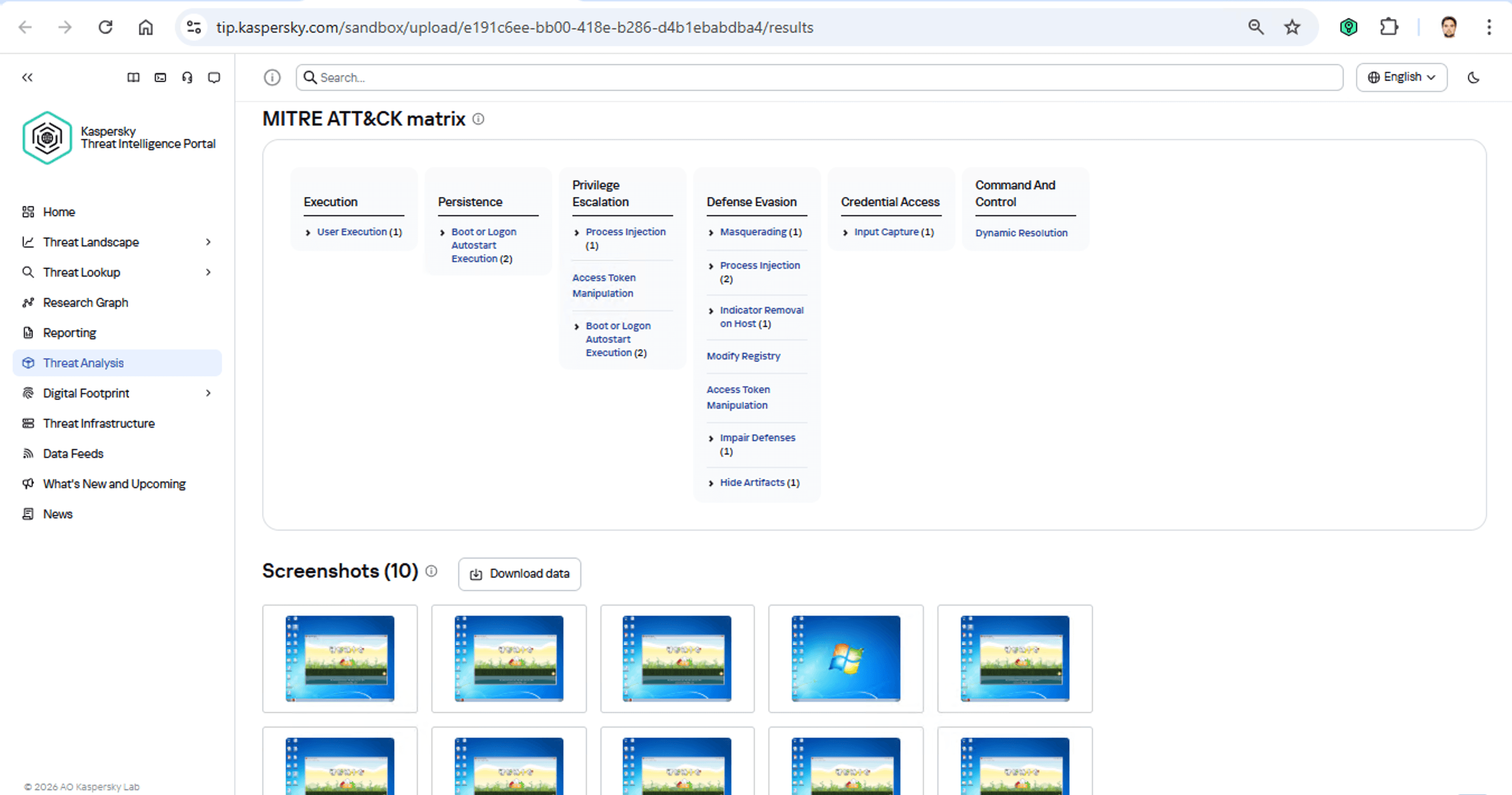
La base de este método es la categorización de la actividad de malware utilizando el marco MITRE ATT&CK. Los informes de entornos de pruebas generalmente contienen una lista de los TTP detectados. Si bien estos son datos muy útiles, no son suficientes para hacer una atribución completa a un grupo específico. Tratar de identificar a los autores de un ataque usando solo este método se parece mucho a la antigua parábola india de los ciegos y el elefante: las personas con los ojos vendados tocan diferentes partes de un elefante e intentan deducir lo que tienen frente a ellos a partir de eso. El que toca la trompa cree que es una pitón, el que toca el costado está seguro de que es una pared, y así sucesivamente.

Atribución técnica
El segundo método de atribución se maneja a través del análisis de código estático (pero ten en cuenta que este tipo de atribución siempre es problemática). La idea central aquí es agrupar incluso los archivos de malware que se superponen ligeramente en función de determinadas características únicas. Antes de que pueda comenzar el análisis, se debe desensamblar la muestra de malware. El problema es que, junto con los bits informativos y útiles, el código recuperado está muy contaminado. Si el algoritmo de atribución tiene en cuenta estos elementos no informativos, cualquier muestra de malware acabará pareciéndose a una gran cantidad de archivos legítimos, lo que hace que realizar una atribución de calidad sea imposible. Por otro lado, intentar atribuir el malware únicamente en función de los fragmentos útiles pero utilizando un método matemáticamente primitivo solo hará que la tasa de falsos positivos se dispare. Además, se debe analizar cualquier resultado de atribución en busca de similitudes con archivos legítimos, y la calidad de esa verificación suele depender en gran medida de las capacidades técnicas del proveedor.
El enfoque de Kaspersky para la atribución
Nuestros productos hacen uso de una base de datos única de malware asociada con grupos de ciberdelincuencia específicos, desarrollada a lo largo de más de 25 años. Además de eso, utilizamos un algoritmo de atribución patentado basado en el análisis estático de código desensamblado. Esto nos permite determinar (con alta precisión e incluso con un porcentaje de probabilidad específico) cómo de similar es un archivo analizado a las muestras conocidas de un grupo en particular. De esta manera, podemos formar un veredicto bien fundamentado que atribuya el malware a un actor de amenazas específico. Los resultados se comparan con una base de datos de miles de millones de archivos legítimos para filtrar los falsos positivos. Si se encuentra una coincidencia con alguno de ellos, el veredicto de atribución se ajusta en consecuencia. Este enfoque es el eje principal de Kaspersky Threat Attribution Engine, que alimenta el servicio de atribución de amenazas en el Kaspersky Threat Intelligence Portal .

 Consejos
Consejos