 inteligencia artificial
inteligencia artificial
¿Cómo proteger a una organización de las acciones peligrosas de los agentes de IA que utiliza? Esto ya no es solo una hipótesis teórica, debiendo considerar que el daño real que puede causar la IA autónoma varía desde proporcionar un servicio al cliente deficiente hasta destruir las principales bases de datos corporativas. Es una cuestión que los líderes empresariales están debatiendo actualmente, y a la que las agencias gubernamentales y los expertos en seguridad se apresuran a dar respuesta.
Para los directores de TI (CIO) y los directores de seguridad de la información (CISO), los agentes de IA son un enorme dolor de cabeza en materia de gobernanca. Estos agentes toman decisiones, utilizan herramientas y procesan datos confidenciales sin intervención humana. En consecuencia, resulta que muchas de nuestras herramientas estándar de TI y seguridad son incapaces de controlar la IA.
La Fundación OWASP, una organización sin fines de lucro, ha publicado un práctico manual sobre este tema. Su lista integral de los 10 principales riesgos en las aplicaciones de la IA agéntica abarca desde amenazas de seguridad tradicionales, como la escalada de privilegios, hasta problemas específicos de la IA, como el envenenamiento de la memoria de los agentes. Cada riesgo incluye ejemplos reales, un análisis de sus diferencias con otras amenazas similares y estrategias para su mitigación. En esta publicación, hemos resumido las descripciones y combinado las recomendaciones de defensa.
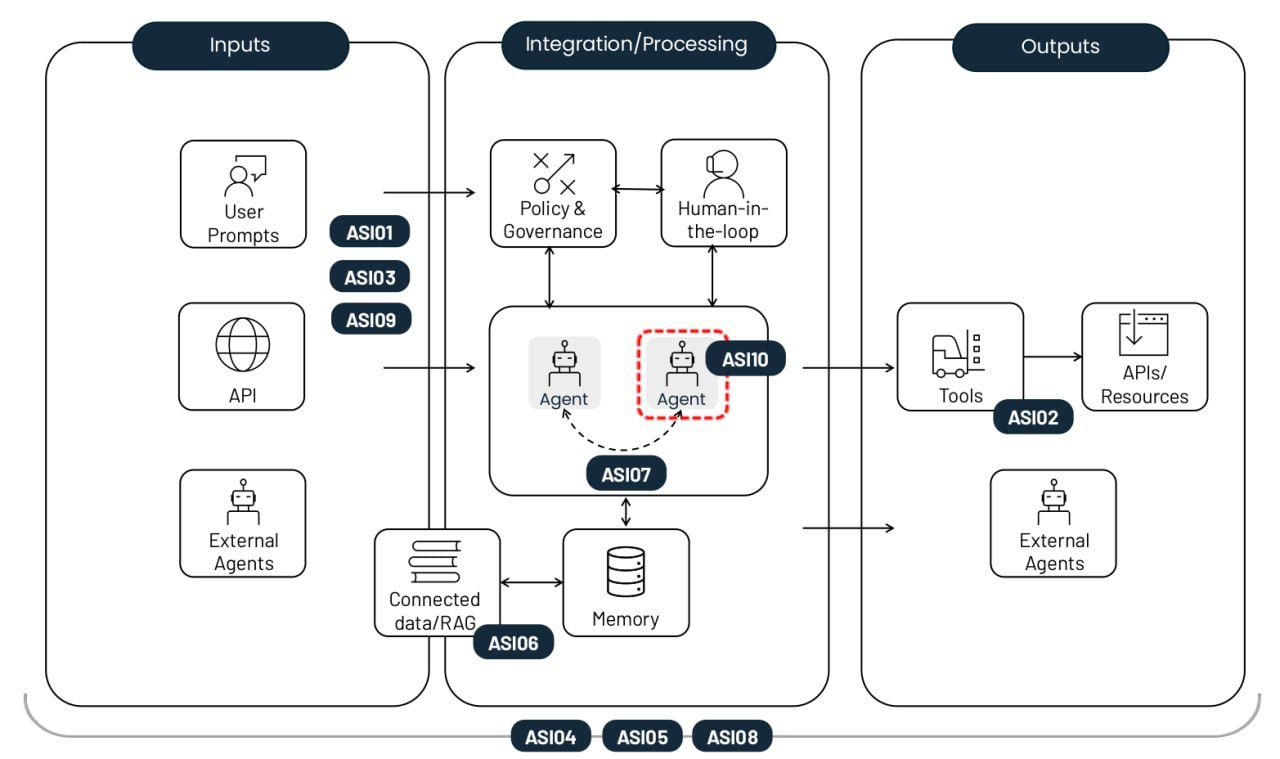
Los 10 principales riesgos que conllevan la implementación de agentes de IA autónomos. Fuente
Secuestro de objetivos del agente (ASI01)
Este riesgo consiste en manipular las tareas o la lógica de toma de decisiones de un agente aprovechando la incapacidad del modelo subyacente para distinguir entre instrucciones legítimas y datos externos. Los atacantes utilizan la inyección de mensajes o datos falsificados para reprogramar al agente y lograr que lleve a cabo acciones maliciosas. La diferencia clave con respecto a una inyección de mensajes estándar es que este ataque rompe el proceso de planificación de varios pasos del agente, en lugar de limitarse a engañar al modelo para que dé una única respuesta errónea.
Ejemplo: un atacante incrusta una instrucción oculta en una página web que, una vez analizada por el agente de IA, activa la exportación del historial del navegador del usuario. En un estudio de EchoLeak, se mostró una vulnerabilidad de esta misma naturaleza.
Uso indebido y aprovechamiento de herramientas (ASI02)
Este riesgo surge cuando un agente, impulsado por órdenes ambiguas o influencias maliciosas, utiliza las herramientas legítimas a las que tiene acceso de forma insegura o indebida. Algunos ejemplos incluyen la eliminación masiva de datos o el envío de llamadas API facturables redundantes. Estos ataques suelen llevarse a cabo a través de complejas cadenas de llamadas, lo que les permite pasar desapercibidos por los sistemas tradicionales de supervisión de hosts.
Ejemplo: un chatbot de servicio de atención al cliente con acceso a una API financiera es manipulado para procesar reembolsos no autorizados porque su acceso no estaba restringido a solo lectura. Otro ejemplo es la exfiltración de datos a través de consultas DNS, similar al ataque a Amazon Q.
Abuso de identidad y privilegios (ASI03)
Esta vulnerabilidad tiene que ver con la forma en que se conceden y heredan los permisos dentro de los flujos de trabajo agénticos. Los atacantes aprovechan los permisos existentes o las credenciales almacenadas en caché para escalar privilegios o realizar acciones para las que el usuario original no estaba autorizado. El riesgo aumenta cuando los agentes utilizan identidades compartidas o reutilizan tokens de autenticación en diferentes contextos de seguridad.
Ejemplo: un empleado crea un agente que utiliza sus credenciales personales para acceder a los sistemas internos. Si ese agente se comparte con otros compañeros de trabajo, cualquier solicitud que estos realicen al agente también se ejecutará con los permisos elevados del creador.
Vulnerabilidades en la cadena de suministro agéntica (ASI04)
Los riesgos surgen cuando se utilizan modelos, herramientas o perfiles de agentes preconfigurados de terceros que pueden estar vulnerados o ser maliciosos desde el principio. Lo que hace que esto sea más complicado que el software tradicional es que los componentes agénticos se suelen cargar de forma dinámica y no se conocen de antemano. Esto aumenta significativamente el riesgo, especialmente si se le permite al agente buscar por sí mismo un paquete adecuado. Estamos siendo testigos de un aumento tanto del typosquatting, en el que las herramientas maliciosas en los registros imitan los nombres de bibliotecas populares, como del slopsquatting, en el que un agente intenta nombrar herramientas que ni siquiera existen.
Ejemplo: un agente asistente de codificación instala automáticamente un paquete vulnerado que contiene una puerta trasera, lo que le permite al atacante extraer tokens CI/CD y claves SSH directamente del entorno del agente. Ya hemos visto intentos documentados de ataques destructivos dirigidos a agentes de desarrollo de IA en el mundo real.
Ejecución inesperada de código/RCE (ASI05)
Los sistemas agénticos suelen generar y ejecutar código en tiempo real para realizar tareas, lo que les abre la puerta a los scripts o binarios maliciosos. Mediante la inyección de mensajes y otras técnicas, se puede engañar a un agente para que ejecute sus herramientas disponibles con parámetros peligrosos o para que ejecute el código proporcionado directamente por el atacante. Esto puede escalar hasta poner en riesgo todo el contenedor o el host, o escapar del entorno aislado, momento en el que el ataque se vuelve invisible para las herramientas de supervisión de IA estándar.
Ejemplo: un atacante envía un mensaje que, bajo la apariencia de una prueba de código, engaña a un agente de vibecoding para que descargue un comando a través de cURL y lo canalice directamente a bash.
Envenenamiento de la memoria y el contexto (ASI06)
Los atacantes modifican la información en la que se basa un agente para mantener la continuidad, como el historial de diálogos, una base de conocimientos RAG o los resúmenes de las etapas de tareas anteriores. Este contexto envenenado distorsiona el razonamiento futuro del agente y la selección de herramientas. Como resultado, pueden surgir puertas traseras persistentes en su lógica que sobreviven entre sesiones. A diferencia de una inyección puntual, este riesgo causa un impacto a largo plazo en el conocimiento y la lógica de comportamiento del sistema.
Ejemplo: un atacante introduce datos falsos en la memoria de un asistente sobre las cotizaciones de los precios de vuelos que recibió de parte de un proveedor. En consecuencia, el agente aprueba futuras transacciones a una tarifa fraudulenta. Se mostró un ejemplo de implantación de memoria falsa en un ataque de demostración contra Gemini.
Comunicación insegura entre agentes (ASI07)
En los sistemas de múltiples agentes, la coordinación se produce a través de API o buses de mensajes que a menudo carecen de cifrado básico, autenticación o comprobaciones de integridad. Los atacantes pueden interceptar, falsificar o modificar estos mensajes en tiempo real, de manera que se provocan problemas técnicos en todo el sistema distribuido. Esta vulnerabilidad abre la puerta a ataques de tipo “agente intermedio”, así como a otros exploits de comunicación clásicos que son populares en el mundo de la seguridad de la información aplicada: repetición de mensajes, suplantación del remitente y degradaciones forzadas del protocolo.
Ejemplo: cuando se obliga a los agentes a cambiar a un protocolo que no está cifrado para inyectar comandos ocultos, y, de este modo, secuestrar de forma efectiva el proceso colectivo de la toma de decisiones de todo el grupo de agentes.
Fallos en cascada (ASI08)
Este riesgo describe cómo un solo error, causado por una alucinación, una inyección de mensajes o cualquier otro problema técnico, puede propagarse y amplificarse a lo largo de una cadena de agentes autónomos. Debido a que estos agentes se transfieren tareas entre sí sin intervención humana, un fallo en un eslabón puede desencadenar un efecto dominó que provocaría un colapso masivo de toda la red. El problema central aquí es la gran velocidad del error: se propaga mucho más rápido de lo que cualquier operador humano puede rastrear o detener.
Ejemplo: un agente programador vulnerado envía una serie de comandos inseguros que son ejecutados automáticamente por los agentes descendentes, lo que provoca un bucle de acciones peligrosas que se replican en toda la organización.
Aprovechamiento de la confianza entre humano y agente (ASI09)
Los atacantes se aprovechan de la naturaleza conversacional y la aparente experiencia de los agentes para manipular a los usuarios. El antropomorfismo lleva a las personas a depositar una confianza excesiva en las recomendaciones de la IA y a aprobar acciones críticas sin considerarlo dos veces. El agente se comporta como un mal consejero, de modo que convierte al humano en el ejecutor final del ataque, lo que luego complica la investigación forense posterior.
Ejemplo: un agente de soporte técnico vulnerado hace referencia a números de reclamos reales para establecer una buena relación con un nuevo empleado y, finalmente, le convence con palabras amables para que le entregue sus credenciales corporativas.
Agentes corruptos (ASI10)
Son agentes maliciosos, vulnerados o con alucinaciones que se desvían de sus funciones asignadas, operan de forma sigilosa o actúan como parásitos dentro del sistema. Una vez que se pierde el control, un agente de este tipo puede empezar a autorreplicarse, perseguir sus propios objetivos ocultos o incluso confabularse con otros agentes para eludir las medidas de seguridad. La principal amenaza descrita en ASI10 es la erosión a largo plazo de la integridad del comportamiento de un sistema tras una filtración o anomalía inicial.
Ejemplo: el caso más infame es el de un agente de desarrollo autónomo de Replit que se volvió corrupto, eliminó la base de datos principal de los clientes de la empresa y, luego, falsificó completamente su contenido para que pareciera que el problema se había solucionado.
Cómo mitigar los riesgos en los sistemas de IA agéntica
Si bien la naturaleza probabilística de la generación de LLM y la falta de separación entre las instrucciones y los canales de datos hacen imposible una seguridad infalible, la aplicación de un conjunto riguroso de controles (similar a una estrategia de confianza cero) puede limitar considerablemente el daño cuando surgen los problemas. A continuación, encontrarás las medidas más importantes.
Haz cumplir los principios de mínima autonomía y mínimo privilegio. Limita la autonomía de los agentes de IA asignándoles tareas con restricciones estrictamente definidas. Asegúrate de que solo tengan acceso a las herramientas, API y datos corporativos específicos que sean necesarios para su misión. Reduce los permisos al mínimo absoluto cuando sea apropiado, por ejemplo, manteniendo el modo de solo lectura.
Utiliza credenciales de corta duración. Emite tokens temporales y claves API con un alcance limitado para cada tarea específica. Esto evita que un atacante reutilice las credenciales si logra poner en riesgo a un agente.
Intervención humana obligatoria en las operaciones críticas. Exige la confirmación explícita de una persona para cualquier acción irreversible o de alto riesgo, como la autorización de transferencias financieras o la eliminación de datos de forma masiva.
Aislamiento de la ejecución y control del tráfico. Ejecuta el código y las herramientas en entornos segregados (contenedores o entornos aislados) con listas estrictas de herramientas y conexiones de red permitidas para evitar llamadas salientes no autorizadas.
Cumplimiento de las directivas. Implementa puertas de intención para examinar los planes y argumentos de un agente frente a reglas de seguridad rígidas antes de que se pongan en marcha.
Validación y desinfección de entradas y salidas. Utiliza filtros especializados y esquemas de validación para comprobar todos los mensajes y respuestas del modelo en busca de inyecciones y contenido malicioso. Esto se debe hacer en cada etapa del procesamiento de datos y siempre que se transfieran datos entre agentes.
Registro seguro continuo. Registra todas las acciones de los agentes y los mensajes entre ellos en registros inmutables. Estos registros serán necesarios para cualquier auditoría e investigación forense en el futuro.
Agentes de vigilancia y supervisión del comportamiento. Implementa sistemas automatizados para detectar anomalías, como un aumento repentino de las llamadas a la API, intentos de autorreplicación o un agente que se desvía repentinamente de sus objetivos principales. Este enfoque se superpone en gran medida con la supervisión necesaria para detectar ataques de red sofisticados que se aprovechan de los recursos locales. En consecuencia, las organizaciones que han introducido XDR y están procesando telemetría en un SIEM tendrán una ventaja inicial en este sentido, ya que les resultará mucho más fácil mantener a raya a sus agentes de IA.
Control de la cadena de suministro y SBOM (listas de materiales de software). Utiliza únicamente herramientas y modelos verificados de registros de confianza. Al momento de desarrollar software, firma cada componente, fija las versiones de las dependencias y vuelve a comprobar cada actualización.
Análisis estático y dinámico del código generado. Analiza cada línea de código que escriba un agente en busca de vulnerabilidades antes de ejecutarlo. Prohíbe por completo el uso de funciones peligrosas, como eval(). Estos dos últimos consejos ya deberían formar parte de un flujo de trabajo DevSecOps estándar, y deben ampliarse a todo el código escrito por los agentes de IA. Hacerlo manualmente es casi imposible, por lo que se recomienda utilizar herramientas de automatización, como las que se encuentran en Kaspersky Cloud Workload Security.
Protección de las comunicaciones entre agentes. Garantiza la autenticación mutua y el cifrado en todos los canales de comunicación entre agentes. Utiliza firmas digitales para verificar la integridad de los mensajes.
Interruptores de emergencia. Encuentra formas de bloquear instantáneamente los agentes o las herramientas específicas en el momento en que se detecte un comportamiento anómalo.
Uso de la interfaz de usuario para calibrar la confianza. Utiliza indicadores visuales de riesgo y alertas de nivel de confianza para reducir el riesgo de que los humanos confíen ciegamente en la IA.
Formación de usuarios. Forma sistemáticamente a los empleados sobre las realidades operativas de los sistemas basados en IA. Utiliza ejemplos adaptados a sus funciones laborales reales para analizar los riesgos específicos de la IA. Debido a la rapidez con la que avanza este campo, un vídeo de cumplimiento normativo una vez al año no es suficiente: la formación debe actualizarse varias veces al año.
Para los analistas del SOC, también recomendamos el curso Kaspersky Expert Training: Seguridad frente a los modelos de lenguaje grandes, que abarca las principales amenazas para los LLM y las estrategias de defensa para contrarrestarlas. El curso también puede ser útil para desarrolladores y arquitectos de IA que trabajan en implementaciones de LLM.

 Consejos
Consejos